The enterprise learning market is undergoing what appears to be an AI transformation. Vendors are announcing AI tutors/coaches, personalized learning paths, automated content generation, and skills intelligence platforms. The vision is compelling: adaptive systems that understand each learner, generate explanations, and predict exactly what training someone needs next.
For customer training specifically, we believe this vision is being built on the wrong foundation.
The problem isn’t that AI capabilities are overhyped — many genuinely work in the right context. The problem is that traditional LMS platforms are trying to add AI features to an architecture designed for a different era. You can’t bolt search-first, intent-driven AI onto enrollment-gated, completion-tracked course systems and expect it to work.
Here’s where the industry thinks customer training is heading, where it’s actually going, and why the gap between the two matters more than the AI capabilities themselves.
A Note Before We Begin
This isn’t an argument against courses entirely. Beetsol supports both search-first access AND traditional structured courses when linear progression matters (onboarding workflows, certification programs). The difference is architectural: customers aren’t forced to enroll in courses to access individual answers. Content is searchable AND can be organized into learning paths when needed, with progress automatically rolling up. See how modular learning architecture makes this possible technically.
The critique here is platforms that ONLY offer course-based access, making search an afterthought rather than the foundation.
The AI Vision Everyone Is Building Toward
Current thinking in enterprise learning technology centers on five capabilities:
AI Personal Tutors or Coaches that answer questions, provide real-time coaching, and adapt explanations based on role and experience level.
Automated Content Generation that creates training modules from documentation, generates assessments automatically, and produces localized content without human authoring.
Personalized Learning Paths that predict what each learner needs next, adapt difficulty dynamically, and route people through content based on behavioral signals.
Skills Intelligence that infers competencies from learning behavior, maps capabilities to organizational needs, and identifies skill gaps automatically.
Experience Customization with sophisticated UI builders, allowing branded academies with custom dashboards and personalized interfaces for different segments.
This is the roadmap most incumbent LMS vendors are following. It’s coherent, well-funded, and technically impressive. For customer training, we believe it’s solving for the wrong problem.
The AI Architecture Divide
Before looking at why traditional platforms struggle, you must understand the two fundamentally different ways AI is being deployed in learning platforms today. Most vendors use “AI-powered” to describe generative systems. True intent-resolution requires retrieval systems.
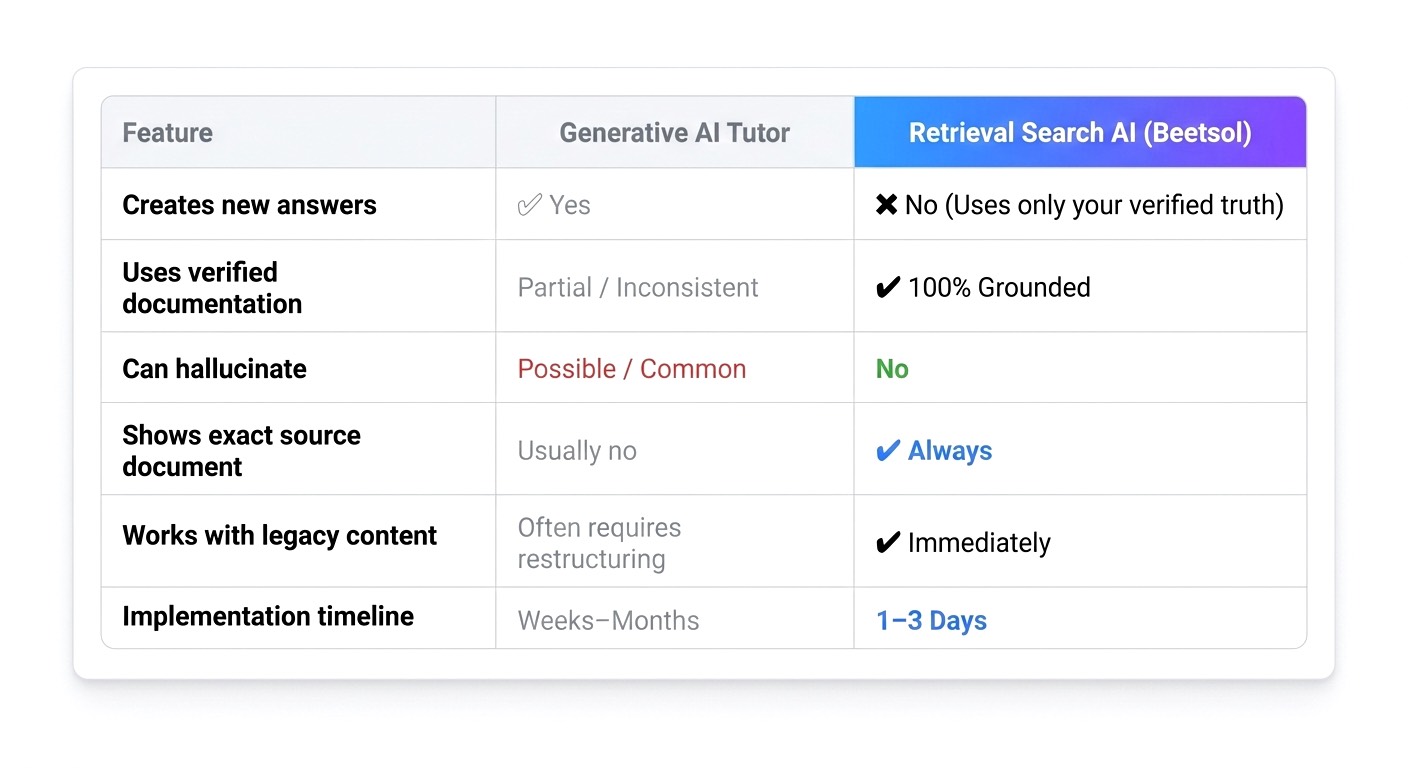
| Feature | Generative AI Tutor | Retrieval-Grounded Search |
|---|---|---|
| Creates new answers | ✔ Yes | ✖ No (Uses only your verified truth) |
| Uses verified documentation | Partial / Inconsistent | ✔ 100% Grounded |
| Can hallucinate | Possible / Common | No |
| Shows exact source document | Usually no | ✔ Always |
| Works with legacy content | Often requires restructuring | ✔ Immediately |
| Implementation timeline | Weeks–Months | 1–3 Days |
{kind=link}
For a visual comparison of cost, implementation speed, and adoption outcomes between these two architectural approaches, see the full metrics breakdown in our Strategy Guide.
Why Traditional Platforms Can’t Deliver (Even With AI)
The issue isn’t AI capability — it’s architectural compatibility. Traditional LMS platforms were built around three core assumptions that made sense for employee training but create fundamental conflicts with how customers actually learn.
These architectural problems — enrollment gates, sequential dependencies, completion-as-success — are the reason traditional LMS platforms consistently deliver only 20-25% adoption for customer training, regardless of AI capabilities. Customers are voluntary learners who reject friction that employees would tolerate. We break down this mandatory-vs-voluntary divide and its financial consequences in detail in Why Your Customer Training Academy Has 25% Adoption.
The short version: course-based architecture was designed for captive audiences. Bolting AI onto the wrong foundation doesn’t fix the foundation.
The Architecture Problem: Five Ways Retrofitting AI Fails
Remember the generative vs. retrieval divide from earlier? This is where that architectural choice creates measurable business impact.
Incumbent platforms, built on course-enrollment-completion architecture, are adding AI capabilities by wrapping AI APIs around existing systems. It’s architectural mismatch disguised as innovation.
Problem 1: AI Tutors That Hallucinate by Design
Most AI tutors in traditional platforms generate responses using language models trained on general SaaS knowledge. When a customer asks about your specific implementation of role hierarchies, the AI tutor generates an answer based on common RBAC (Role-Based Access Control) patterns — not your actual product documentation.
This is hallucination by design, not a bug. The AI doesn’t have direct access to your verified content, so it synthesizes plausible-sounding explanations that may be 70-95% correct for your specific product.
Some AI authoring tools are even worse — they generate entire training modules and assessments without referencing your existing documentation at all.
Problem 2: Content Generation Without Migration Strategy
Here’s the hidden technical reason AI content generation struggles: Most traditional LMS platforms store content in relational databases (MySQL, PostgreSQL without vector extensions) optimized for course structures and completion tracking. The database doesn’t ‘know’ that your 2021 SSO guide, 2023 API redesign, and 2025 authentication overhaul are all related to the same concept.
So vendors tell you: “We’ll help you restructure your content library.” Translation: 3-6 months manually retagging and reorganizing so the AI has clean input.
Platforms built on vector databases from day one can semantically search messy, legacy content immediately. Upload a 2019 PDF about webhooks next to a 2025 video about the same topic — the vector layer understands they’re related, even if terminology changed.
This is the technical foundation behind semantic deep search — intent-based retrieval that works across formats and terminology shifts.
But the structural flaw is only half the problem: Most bolt-on AI tools lack a retrieval layer connected directly to your knowledge base. Instead of pulling from your verified help articles, they feed basic keywords into an LLM to generate lessons. You aren’t training customers on your specific software; you’re serving them generic, synthesized information that isn’t grounded in your single source of truth.
Problem 3: The 1 × 1000 Problem (The Hallucination Tax)
When traditional platforms bolt on generative AI tutors, they introduce stochastic risk into the exact moment customer trust is most fragile.
If a generative AI tutor gives a customer a configuration answer that is 95% correct but misses one critical, product-specific step, the configuration fails. If 47 customers receive that same confidently wrong answer over three weeks, they all fail. They don’t blame the AI; they assume your product is broken.
47 frustrated customers opening support tickets at $50 per resolution creates an immediate Hallucination Tax of over $2,000 — just from one slightly inaccurate AI response. Because search-first architecture uses grounded retrieval (pointing strictly to verified documentation), this scalable hallucination risk is entirely eliminated.
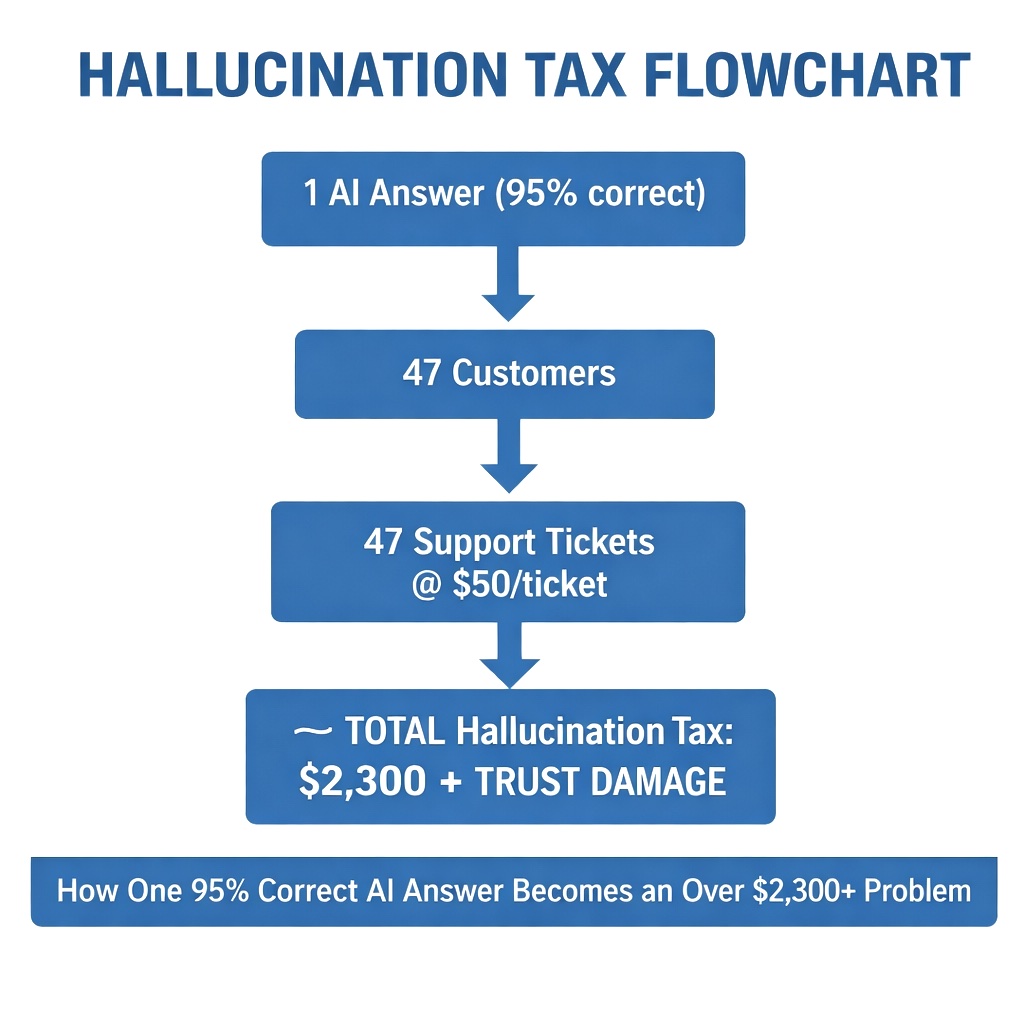
At enterprise scale, the Hallucination Tax compounds. Consider a platform with 500 customer accounts averaging 20 active users each. If a generative AI tutor handles 200 configuration queries per week and hallucinates on just 2% of responses, that’s 4 incorrect answers weekly. Over a quarter, roughly 50 customers receive confidently wrong guidance. At $50 per resulting support ticket plus $200 in average CS escalation time per failed configuration, one hallucinating feature costs over $12,500 per quarter — not counting the trust erosion that accelerates churn.
This is why retrieval-grounded architecture isn’t just technically preferable — it’s financially necessary. To calculate the specific support deflection ROI for your customer base, use the Beetsol ROI calculator. For a framework on measuring these training economics, see Customer Training ROI: The Metrics That Actually Reduce Churn.
Problem 4: Version Conflicts at Scale
You have documentation about Feature X from 2021 (deprecated), 2023 (some customers still on this version), and 2025 (current). Course-based systems must create separate courses for each version, or update the course and lose historical context, or manually tag everything and hope customers pick the right version-specific course.
What actually happens: Contradictory content exists across courses. Customers find old information. Configurations fail. Support tickets open.
AI content generation makes this worse because the AI doesn’t inherently understand which content is current, which is deprecated, and which applies to specific customer segments.
Example: A project management SaaS that ships quarterly releases has customers on versions 3.2, 3.3, and 4.0 simultaneously. In a course-based system, you need three parallel course trees — “User Permissions (v3.2),” “User Permissions (v3.3),” “User Permissions (v4.0)” — each requiring separate enrollment paths, separate completion tracking, and separate maintenance.
In a retrieval-based system, all three documentation versions coexist. When a customer on v3.3 searches “how do I set role permissions,” the semantic layer surfaces the v3.3-specific answer directly. No parallel course trees. No version-gating. The system resolves version context the same way it resolves intent — automatically.
Problem 5: Personalization Without Behavioral Data
Personalized learning paths require knowing what someone is trying to accomplish. In course-based systems, the only signals are:
- Which courses they enrolled in
- Which modules they completed
- How much time they spent
These signals reveal almost nothing about actual learning needs. A customer who spent 8 minutes in “Advanced API Integration” might have been:
- Deeply engaged and learning
- Confused and searching for a specific answer
- In the wrong module entirely
- Watching a video while on a call (tab open but not paying attention)
AI personalization built on completion data is sophisticated guesswork.
The Search-First Alternative: Intent Over Enrollment
Customer training needs to be built around search and intent resolution, not enrollment and completion. This isn’t just “add better search to an LMS.” It’s a fundamentally different architecture where search is the primary interface and content is atomized for retrieval, not sequenced into courses. This doesn’t eliminate courses — it makes them optional. When you need structured onboarding workflows or formal certification programs, create courses and progress automatically rolls up. When customers need instant answers, they search and find content directly. Same platform, both access models.
How Search-First Architecture Works
A search-first architecture doesn’t mean ‘course-less’— it simply means search is the primary access model, with courses available when linear progression matters. On this hybrid foundation, core LMS capabilities backed by AI function entirely differently:
- Content as Atomic Units
Instead of modules nested in courses, content exists as standalone, searchable pieces. Each addresses a specific question(s) or task(s). No prerequisites. A customer searching “SSO configuration” gets the specific SSO setup guide — not a course enrollment page.
- Semantic Search, Not Keyword Matching
Vector embeddings understand intent. Customer searches: “how do I let someone access my project” — Semantic search matches this to “User Permissions,” “Invite Team Members,” “Project Access Settings,” and “Role Management” even though there’s no keyword overlap.
See how deep search uses vector embeddings to match customer questions to content based on semantic similarity, not just keywords.
- Grounded Generation with Source Attribution
Here’s where Beetsol’s approach differs from both pure retrieval and pure generation:
When a customer searches, the system:
- Uses semantic search to find the exact intent within your documentation
- Processes the retrieved context through our secure RAG layer
- Returns a concise, accurate answer WITH clear source attribution
The customer sees: “Based on your SSO Setup Guide and API Authentication documentation, here’s how to configure single sign-on…” with clickable links to the source articles.
This is generative AI, but grounded. If documentation has errors, you fix the source and future summaries are corrected. If content is missing, the system shows gaps — it doesn’t hallucinate plausible-sounding wrong answers.
See how Beetsol’s search-first architecture combines semantic search with grounded generation to deliver accurate, source-attributed answers.
- Intent Resolution Tracking
Instead of measuring course completions, measure:
- Search success rate (did the query return relevant results?)
- Time to resolution (how fast did they find their answer?)
- Content gaps (what did they search for that we don’t have?)
- Support ticket correlation (did they find the answer or open a ticket?)
These metrics reveal actual training effectiveness, not engagement theater. Learn more about intent resolution analytics and search gap tracking.
- Version Management
Content is tagged with version applicability. When a customer searches, the system knows which version they’re on (from product telemetry) and surfaces only relevant documentation. If documentation for their version is missing, the system flags this as a content gap — it doesn’t generate generic answers that might apply to the wrong version.
This is nearly impossible in course-based systems where customers self-select courses without version context.
Why This Matters: Activation and Support Economics
The architectural choice between course-based and search-first isn’t academic — it drives measurable business outcomes.
Customer Activation Velocity
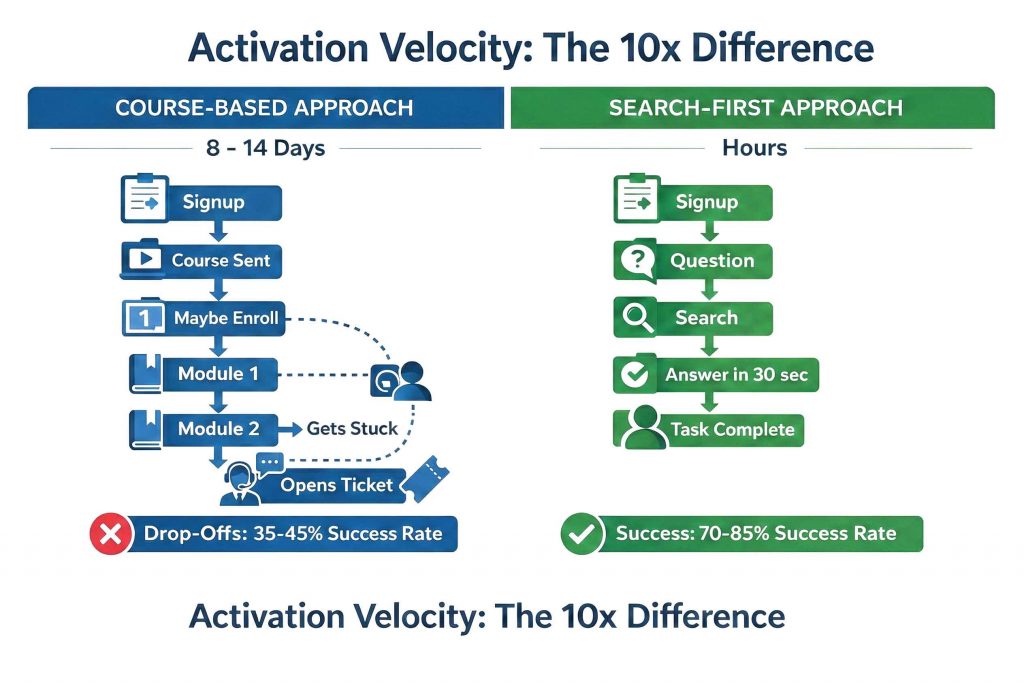
Course-based approach:
New customer signs up → Receives “Getting Started” course → Enrolls (maybe) → Starts Module 1 → Gets stuck on Module 3 → Opens support ticket or churns
Time to first value: 8-14 days if they complete onboarding, never if they don’t.
Search-first approach:
New customer signs up → Encounters first question → Searches in-product → Finds answer in 30 seconds → Completes task → Sees product value → Continues using
Time to first value: Hours, not days.
This isn’t marginal improvement. It’s the difference between activation rates of 35-45% (course-based) and 70-85% (search-first).
The future of customer training isn’t in the sophistication of the AI — it’s in the invisibility of the interface.
If your pricing model is shifting toward usage-based, the stakes of this architectural choice get even higher. See Usage-Based SaaS Requires AI-Speed Adoption.
Support Ticket Economics
40% of B2B SaaS support tickets ask about features that are already documented. At $50 per ticket in fully-loaded internal resolution cost, this is:
- 800 tickets/month × 40% = 320 documented-feature tickets
- 320 × $50 = $16,000/month wasted
- $192,000/year in redundant support costs
Why course-based training doesn’t solve this:
Customers with questions at 2pm on a Monday don’t think “I should check if there’s a course about this.”
They search, fail to find it (because it’s locked behind course enrollment), and open a ticket.
Why search-first training does:
Customer has questions → Searches in-product help → Question answered in 45 seconds → No ticket opened.
Real data from mid-market SaaS implementations: 30-40% ticket reduction within 90 days for documented topics.
The ROI isn’t in sophisticated AI features. It’s in basic findability. Calculate your specific support cost savings using Beetsol’s training ROI calculator.
Architecture Before AI Features
The pattern we’re seeing across enterprise learning vendors:
Successful course-based LMS → AI becomes industry priority → Add AI features (tutors, generation, personalization) → Features are technically impressive but don’t improve core outcomes → Customer training still struggles with findability and activation.
The mistake is treating AI capabilities as features to add rather than asking: “Does our core architecture support what customers actually need?”
- You can build phenomenal AI tutors or coaches, but if customers can’t find their answer through search because it lives inside a course, the capability is irrelevant.
- You can generate perfectly personalized learning paths, but if customers won’t enroll in courses because they just want immediate answers, the personalization is wasted.
- You can create beautiful, branded training portals with sophisticated UI customization, but if customers prefer embedded in-product help that doesn’t require context-switching, the portal goes unused.
These capabilities aren’t wrong for every use case. But for customer training, the foundation matters more than the features.
The industry roadmap focuses on sophistication: smarter AI, better personalization, more automated content generation.
We think customer training is heading toward simplification: instant answers, embedded access, intent resolution.
The Winning Platform
The winning platforms won’t be the ones with the flashiest AI demos. They will be the ones that make the training interface entirely invisible — where finding a verified answer is so frictionless, the customer never even realizes they are learning.
Get the foundation right, then add intelligence. Not the other way around.
That’s not a rejection of AI — it’s clarity about what AI should actually do in customer training. Enhance search, ground generation in verified content, surface gaps, and correlate with outcomes.
Just not from within an enrollment-gated architecture that forces customers into courses for every answer. Courses themselves aren’t the problem — enrollment gates are. Structured learning paths matter for onboarding and certification. But when a customer needs to configure SSO, they shouldn’t have to enroll in Module 3 of Course 2. That’s the architectural conflict. Search-first platforms solve this by making courses optional, not mandatory.
For comprehensive guidance on building search-first customer training programs, see our complete customer training LMS guide.
FAQ
Why can’t traditional LMS platforms just add better search?
They can add search functionality, but the content is still locked behind course enrollment. Even with perfect search results, if clicking a result takes you to a course enrollment page instead of the actual answer, you haven’t solved the findability problem. The traditional LMS architecture requires courses as containers — search becomes navigation to courses, not direct access to answers.
If you’re currently evaluating incumbent platforms, see how search-first architecture compares to Docebo, Skilljar, Thought Industries, Absorb, TalentLMS, or LearnUpon.
Doesn’t Beetsol use generative AI too?
Yes, but grounded in retrieval. When you search, Beetsol finds relevant documentation using semantic search, then uses its RAG layer to summarize those specific articles into a concise answer with source attribution. You see both the summary AND the exact documentation it came from. If the source documentation is wrong, you fix it once and all future summaries are corrected. This is different from pure generative AI that creates answers from scratch without showing sources.
What about companies that need formal certification programs?
Beetsol supports both search-first access AND traditional structured courses when needed. If content is part of a course or certification path, progress automatically rolls up. The difference is you don’t force customers to enroll in a course just to access a single module. Courses exist for when linear progression matters (onboarding workflows, certification programs), but content is also directly searchable for just-in-time answers.
How does search-first architecture handle customers on different product versions?
Content is tagged with version applicability. The system knows which product version each customer is on (from product telemetry or account data). When they search, they only see documentation relevant to their version. If you have customers on v2.1, v2.5, and v3.0 simultaneously, each sees only their applicable content. This is nearly impossible in course-based systems where customers self-select courses without version context.
Won’t customers miss important foundational knowledge if they only search for immediate answers?
Search analytics reveal patterns. If many customers search “advanced API” topics without ever searching fundamentals, that signals a content recommendation opportunity: “Before configuring webhooks, you might find our API Authentication guide helpful.” Intent-based recommendations work better than forced prerequisites because they’re contextual. The customer decides if they need foundational knowledge — the system just makes it easily discoverable.
What’s wrong with investing in better UI customization and branded portals?
Nothing wrong with it for employee training or formal partner programs where people expect designated academies. For customer training, the trend is toward embedded, in-product help — not separate portals. Customers prefer training that appears contextually when they’re stuck, not logging into a separate branded academy. Investing in elaborate portal UIs misses the shift toward “ask-first” interfaces where search happens inline. The best customer training UI is invisible — it just answers questions where customers already are.
How long does it take to see results from search-first training?
Faster than course-based because there’s no adoption curve. With courses, you need customers to discover the academy, browse the catalog, enroll, and complete content. With search-first, you embed help in your product and customers find answers immediately. Typical timeline: Week 1-2 (content uploaded and indexed), Week 3-4 (soft launch, 20% of customers), Week 5-8 (full rollout), Day 60-90 (measurable ticket reduction of 30-40% for documented topics). No waiting for course enrollments or completions.
What if our content isn’t organized into atomic modules — it’s all long-form documentation?
Semantic search works with existing content as-is. Upload your 45-minute technical videos, your comprehensive PDFs, your detailed guides. The system chunks content semantically for retrieval — you don’t restructure everything. A customer searching “SSO configuration” might get pointed to timestamp 14:32 in your authentication video or page 8 of your security PDF. Grounded generation then summarizes that specific section. You can gradually modularize content based on search analytics showing which topics get asked about most frequently, but you’re not blocked from launch.
Isn’t focusing on search and findability just solving a symptom rather than the root cause?
The root cause IS findability for customer training. The problem isn’t that customers don’t want to learn — it’s that they can’t find answers when they have questions. They’re stuck in your product at 2pm with a specific problem. Forcing them to browse a course catalog, enroll in “User Management 101,” and complete Module 1-6 to find the answer in Module 7 is the symptom. Direct, instant access to the specific answer they need is the cure. Course-based architecture treats findability as a secondary problem to solve with better search. Search-first architecture recognizes findability as the primary outcome to design for.